
About Me
I am a Ph.D. student at UC Berkeley, affiliated with Berkeley AI Research (BAIR) Lab and Berkeley DeepDrive (BDD).
My research focuses on 3D computer vision and its applications in Robotics.
Research Interests
Generation
3D/4D Generation
World Models
Reconstruction
Gaussian Splatting
NeRF-SLAM
Perception
Sensor Fusion
Multi-modal Learning
Publications
Selected research papers and preprints. * denotes equal contribution.
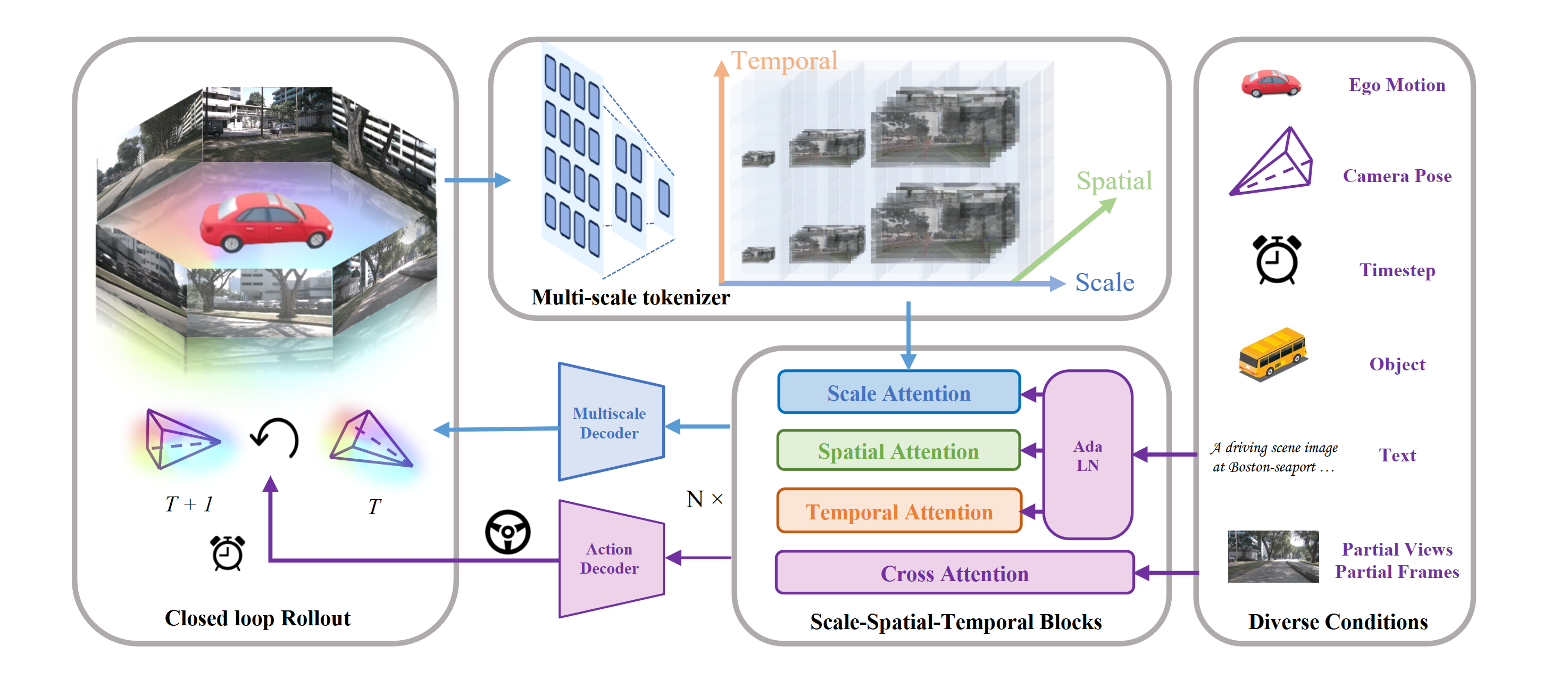
UNICST: Next-scale Latent Prediction for Continuous Spatio-Temporal World Modeling
We introduce UNICST a unified 4D latent world model that jointly learns Continuous Spatio-Temporal representations with minimal inductive bias, enabling seamless, spatio-temporally coherent video generation.
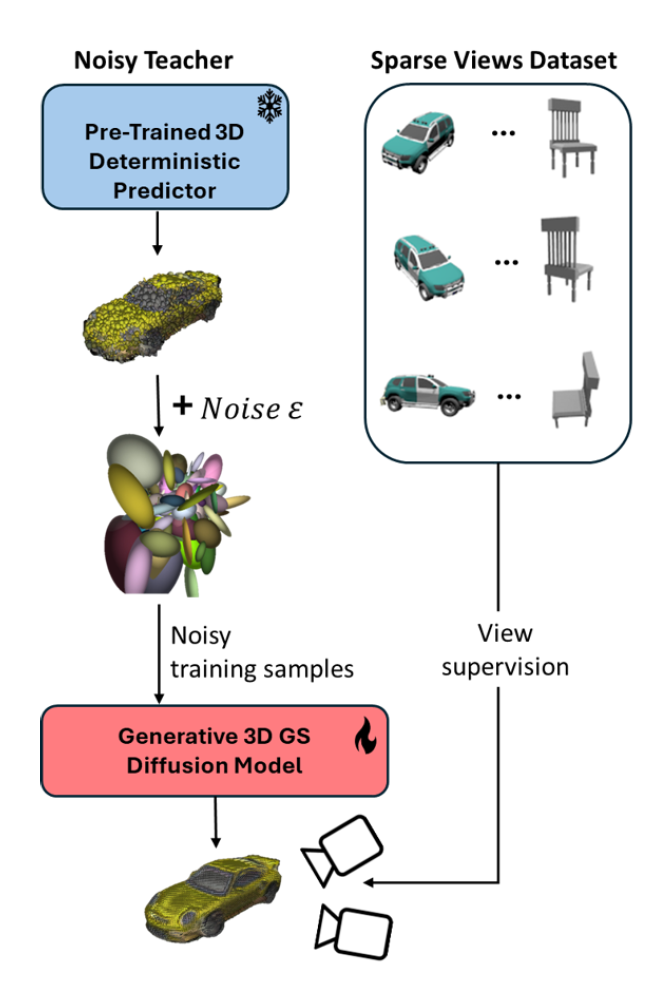
A Lesson in Splats: Teacher-Guided Diffusion for 3D Gaussian Splats Generation
We introduce a diffusion model for Gaussian Splats, SplatDiffusion, to enable generation of three-dimensional structures from single images. Our approach further incorporates a guidance mechanism to aggregate information from multiple views.

DeSiRe-GS: 4D Street Gaussians for Static-Dynamic Decomposition
We present DeSiRe-GS, a self-supervised gaussian splatting representation, enabling effective static-dynamic decomposition and high-fidelity surface reconstruction in complex driving scenarios.

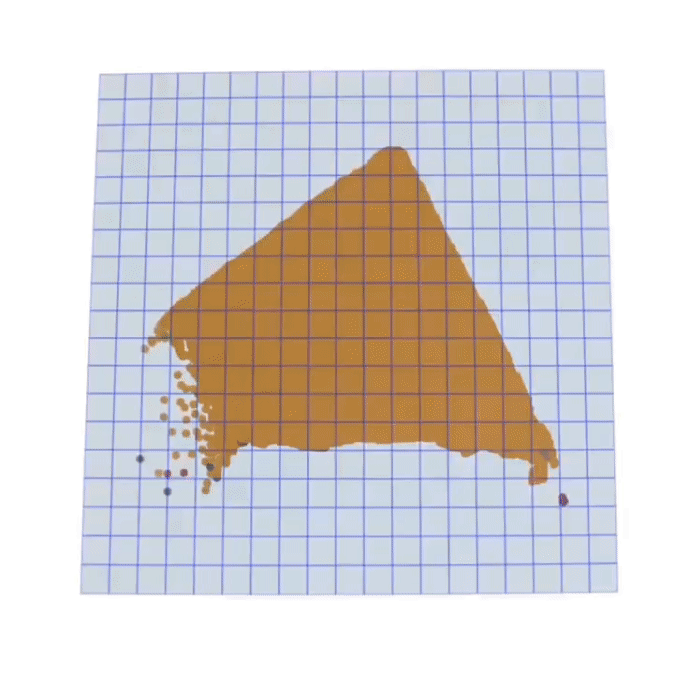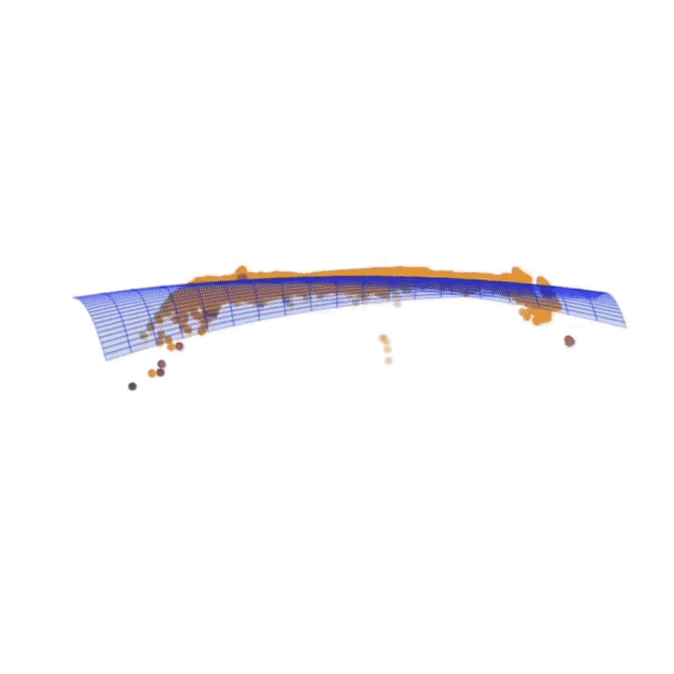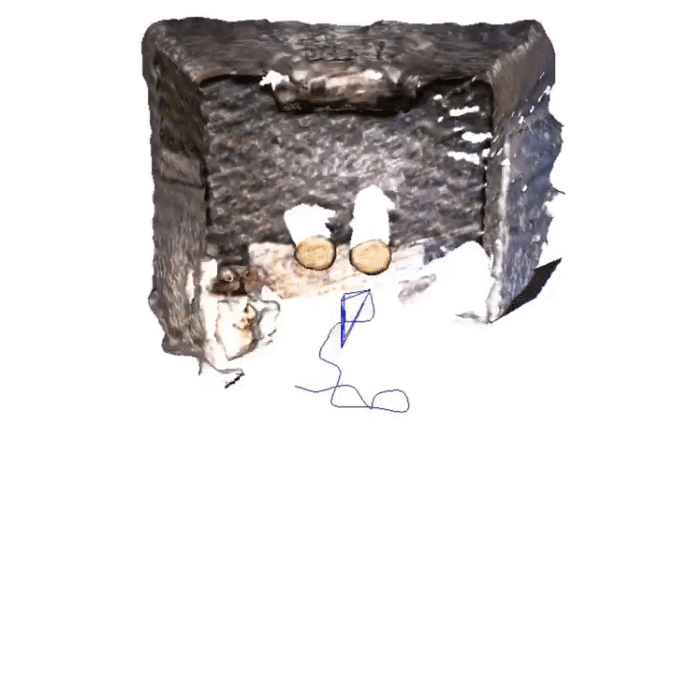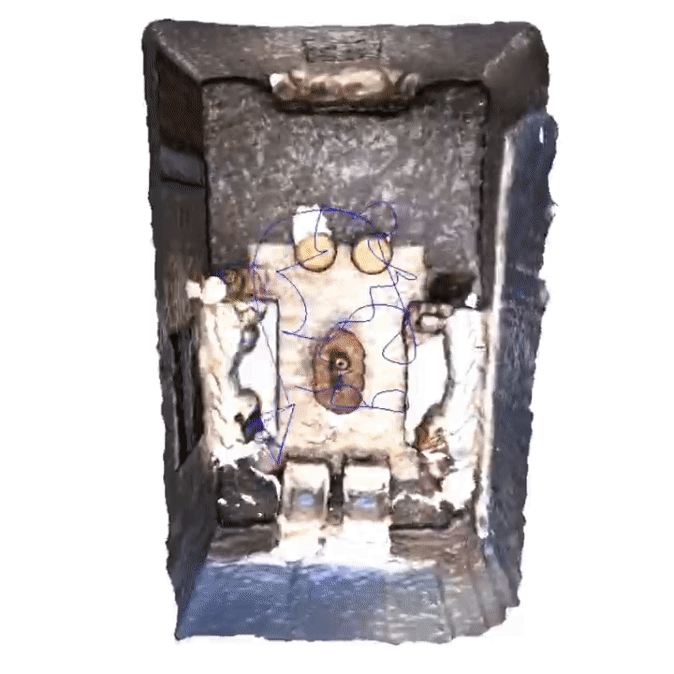
Q-SLAM: Quadric Representations for Monocular SLAM
In this study, we propose a novel approach that reimagines volumetric representations through the lens of quadric forms. We posit that most scene components can be effectively represented as quadric planes. Leveraging this assumption, we reshape the volumetric representations with million of cubes by several quadric planes, which leads to more accurate and efficient modeling of 3D scenes in SLAM contexts.


Interactive multi-scale fusion of 2D and 3D features for multi-object vehicle tracking
In this paper, we propose multi-scale interactive query and fusion between pixel-wise and point-wise features to obtain more discriminative features. In addition, an attention mechanism is utilized to conduct soft feature fusion between multiple pixels and points to avoid inaccurate match problems.
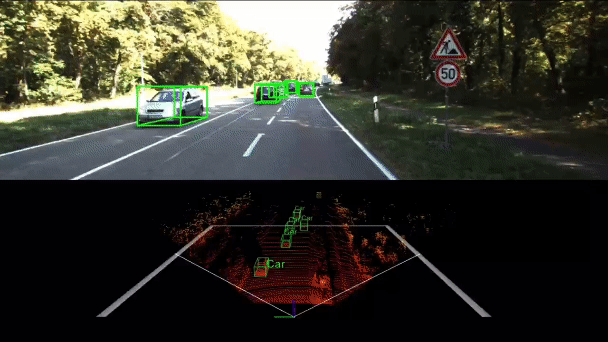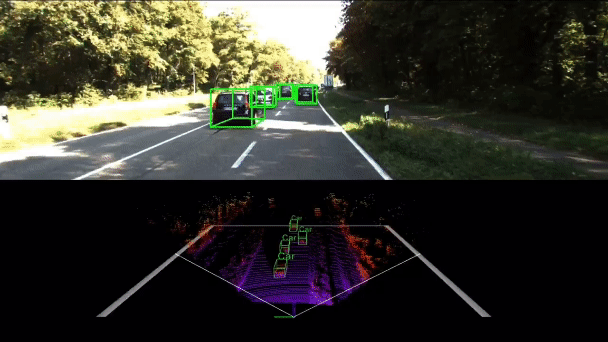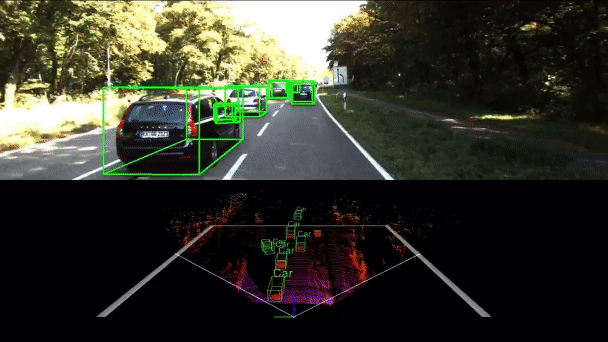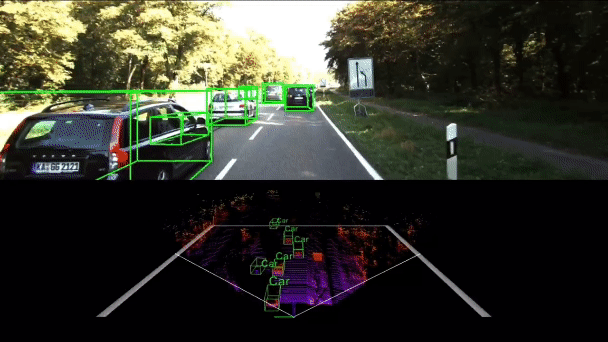
PNAS-MOT: Multi-Modal Object Tracking with Pareto Neural Architecture Search
We explore the use of the neural architecture search (NAS) methods to search for efficient architectures for tracking, aiming for low real-time latency while maintaining relatively high accuracy. We also propose a multi-modal framework to improve the robustness.
Get In Touch
Always open to discussing new ideas, collaborations, or research opportunities.